Cell ergometry
{{MitoPedia |description=Biochemical cell ergometry aims at measurement of JO2max (compare VO2max or VO2peak in exercise ergometry of humans and animals) of cell respiration linked to phosphorylation of ADP to ATP. The corresponding OXPHOS capacity is based on saturating concentrations of ADP, [ADP], and inorganic phosphate [Pi] available to the mitochondria. This is metabolically opposite to uncoupling of respiration, which yields ET capacity. The OXPHOS state can be established experimentally by selective permeabilization of cell membranes with maintenance of intact mitochondria, titrations of ADP and Pi to evaluate kinetically saturating conditions, and establishing fuel substrate combinations which reconstitute physiological TCA cycle function. Uncoupler titrations are applied to determine the apparent ET-pathway excess over OXPHOS capacity ([[E-P control efficiency |E-P control efficiency) and to calculate the P-L control efficiency jP-L and E-L coupling efficiency jE-L. These normalized flux ratios are the basis to calculate the ergometric or ergodynamic efficiency, ε = j · f, where f is the normalized force ratio.
» MiPNet article |info=Gnaiger 2020 BEC MitoPathways, Oxygen flux }}
Cell ergometry and OXPHOS

| Gnaiger E (2015) Cell ergometry and OXPHOS. Mitochondr Physiol Network 2015-01-18. |
Abstract: Spiroergometry on the organismic level is compared to cell ergometry as OXPHOS analysis on the cellular level.
• O2k-Network Lab: AT Innsbruck Gnaiger E
Spiroergometry
- VO2max or VO2peak in cycle or treadmill spiroergometry is expressed in units of [mL O2·min-1·kg-1] body mass. 1 mL oxygen at STPD is equivalent to 22.392 mmol O2. Therefore, multiply by 1000/(22.392·60)=0.744 to convert VO2max to JO2max expressed in SI units [nmol·s-1·g-1]:
1 mL O2·min-1·kg-1 = 0.744 µmol·s-1·kg-1
- VO2max (JO2max) typically declines from 70 to 25 mL O2·min-1·kg-1 (50 to 20 µmol·s-1·kg-1) in the range of healthy trained to obese untrained humans.
Keywords
- Expand Bioblast links to Cell ergometry

The Blue Book 2020

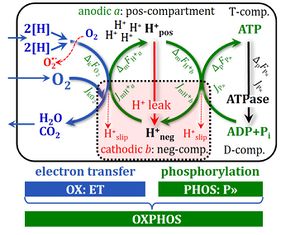
OXPHOS-, ROUTINE-, ET-, and LEAK states; respiratory capacities (P, R, E, L) corrected for residual oxygen consumption Rox.
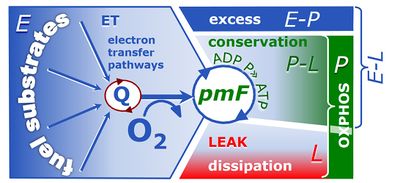
4-compartmental OXPHOS model. (1) ET capacity E of the noncoupled electron transfer system ETS. OXPHOS capacity P is partitioned into (2) the dissipative LEAK component L, and (3) ADP-stimulated P-L net OXPHOS capacity. (4) If P-L is kinetically limited by a low capacity of the phosphorylation system to utilize the protonmotive force pmF, then the apparent E-P excess capacity is available to drive coupled processes other than phosphorylation P» (ADP to ATP) without competing with P».



(P-L)/P is the OXPHOS P-L control efficiency. The biochemical coupling efficiency is independent of kinetic control by the phosphorylation system when expressed as the E-L coupling efficiency, (E-L)/E. (E-P)/E is the kinetic E-P control efficiency.





- Bioblast links: Coupling control - >>>>>>> - Click on [Expand] or [Collapse] - >>>>>>>
1. Mitochondrial and cellular respiratory rates in coupling-control states
| Respiratory rate | Defining relations | Icon | |
|---|---|---|---|
| OXPHOS capacity | P = P´-Rox | mt-preparations | |
| ROUTINE respiration | R = R´-Rox | living cells | |
| ET capacity | E = E´-Rox | » Level flow | |
| » Noncoupled respiration - Uncoupler | |||
| LEAK respiration | L = L´-Rox | » Static head | |
| » LEAK state with ATP | |||
| » LEAK state with oligomycin | |||
| » LEAK state without adenylates | |||
| Residual oxygen consumption Rox | L = L´-Rox |
2. Flux control ratios related to coupling in mt-preparations and living cells
| FCR | Definition | Icon | |
|---|---|---|---|
| L/P coupling-control ratio | L/P | » Respiratory acceptor control ratio, RCR = P/L | |
| L/R coupling-control ratio | L/R | ||
| L/E coupling-control ratio | L/E | » Uncoupling-control ratio, UCR = E/L (ambiguous) | |
| P/E control ratio | P/E | ||
| R/E control ratio | R/E | » Uncoupling-control ratio, UCR = E/L | |
| net P/E control ratio | (P-L)/E | ||
| net R/E control ratio | (R-L)/E |
3. Net, excess, and reserve capacities of respiration
| Respiratory net rate | Definition | Icon |
|---|---|---|
| P-L net OXPHOS capacity | P-L | |
| R-L net ROUTINE capacity | R-L | |
| E-L net ET capacity | E-L | |
| E-P excess capacity | E-P | |
| E-R reserve capacity | E-R |
4. Flux control efficiencies related to coupling-control ratios
| Coupling-control efficiency | Definition | Icon | Canonical term | ||
|---|---|---|---|---|---|
| P-L control efficiency | jP-L | = (P-L)/P | = 1-L/P | P-L OXPHOS-flux control efficiency | |
| R-L control efficiency | jR-L | = (R-L)/R | = 1-L/R | R-L ROUTINE-flux control efficiency | |
| E-L coupling efficiency | jE-L | = (E-L)/E | = 1-L/E | E-L ET-coupling efficiency » Biochemical coupling efficiency | |
| E-P control efficiency | jE-P | = (E-P)/E | = 1-P/E | E-P ET-excess flux control efficiency | |
| E-R control efficiency | jE-R | = (E-R)/E | = 1-R/E | E-R ET-reserve flux control efficiency |
5. General
- » Basal respiration
- » Cell ergometry
- » Dyscoupled respiration
- » Dyscoupling
- » Electron leak
- » Electron-transfer-pathway state
- » Hyphenation
- » Oxidative phosphorylation
- » Oxygen flow
- » Oxygen flux
- » Permeabilized cells
- » Phosphorylation system
- » Proton leak
- » Proton slip
- » Respiratory state
- » Uncoupling
MitoPedia concepts: MiP concept, Ergodynamics
MitoPedia methods:
Respirometry
Labels:
Regulation: Coupling efficiency;uncoupling
Coupling state: LEAK, OXPHOS, ET
Pathway: N, S, NS, ROX
HRR: Theory